Série : Construire son plan de veille ← Précédent : Ep. 2 — Identifier les sources | Suivant : Ep. 4 — Faire vivre le dispositif →
Attention, cet article contient des mentions de droits. Je ne suis pas expert de ce domaine et les éléments légaux apportés ici sont des introductions aux questions de droit que vous devez vous poser dans la rédaction d'un bon plan de surveillance. Dans tous les cas, faites appel à un professionnel des questions légales pour traiter proprement la problématique.
Vous avez fait le travail. Vos menaces sont cartographiées. Vos sources sont identifiées, qualifiées, priorisées. Vous ouvrez les vannes.
Et vous vous noyez.
J'ai vu ce scénario se répéter avec une régularité déconcertante. L'équipe a suivi la méthode, investi du temps sur les deux premières étapes, et au moment de passer à l'opération, elle traite la collecte comme une finalité. Or la collecte n'est qu'un point de départ. Posséder les meilleures sources du monde ne sert à rien si vous n'avez pas l'architecture qui transforme ce flux brut en décision d'action.
Ce système, celui qui relie la source à l'analyste et l'analyste à la décision, c'est le système nerveux de votre plan de veille. Il ne s'improvise pas et c'est justement l'objet de cet épisode.
Pour rappel, nous en sommes à l'étape 4 de la conception de notre plan de surveillance :
- Cartographie et qualification des menaces (Terminé — voir Ep. 1)
- Évaluation et priorisation de la veille (Terminé — voir Ep. 2)
- Cartographie et qualification des sources d'informations (Terminé — voir Ep. 2)
- Identification des systèmes de veille sur les sources d'informations (Cœur de cet article)
- Mise en place du dispositif de surveillance (on défriche)
- Maintenir et faire évoluer la veille dans le temps
Nous allons aborder le point 4 dans son intégralité, et poser les premières briques du point 5.
I. Avant de choisir un outil : comprendre ce qu'on lui demande
L'erreur la plus fréquente et la plus coûteuse que j'ai rencontrée en mission est simple : on achète l'outil avant de définir le besoin. On signe un abonnement à une plateforme CTI parce qu'elle est réputée, parce qu'un concurrent l'utilise, parce qu'on se dit qu'il n'y a probablement rien de plus puissant. Six mois plus tard, l'analyste passe 80 % de son temps à trier des alertes qui ne concernent pas ses menaces prioritaires.
La raison est structurelle. Tout dispositif de surveillance doit répondre à quatre questions, dans un ordre précis.
- Comment est-ce qu'on collecte ?
- Comment est-ce qu'on traite ?
- Comment est-ce qu'on livre ?
- Qui décide, et sur quelle base ?
Ce que j'observe régulièrement, ce sont des investissements massifs dans la réponse à la première question, et une quasi-ignorance des deux suivantes. On se retrouve alors avec un analyste submergé qui ne peut plus répondre à la quatrième question avec la lucidité nécessaire. C'est le syndrome que les Anglo-Saxons appellent l'Alert Fatigue. Votre système est tellement bavard que votre analyste finit par traiter la cinquantième notification de la journée avec la même indifférence que la première. Y compris celle qui comptait vraiment.
Dans les sections qui suivent, nous allons construire chacune des couches permettant de répondre à ces quatre questions. L'objectif n'est pas d'avoir le système le plus sophistiqué, mais celui qui délivre l'information juste, au bon moment, avec le moins de charge possible pour l'humain.
II. La collecte : naviguer entre familles de sources, contraintes techniques et cadre juridique
Collecter une information sur un flux RSS de publications CVE et surveiller un canal Telegram fermé discutant d'une action contre votre infrastructure, ce sont deux opérations radicalement différentes. Les contraintes techniques, les risques opérationnels et le cadre juridique n'ont rien à voir.
Illustrons avec un cas concret. Un analyste fraîchement recruté dans un CERT industriel décide de surveiller un forum underground où des acteurs revendent des accès à des systèmes SCADA. Il crée un compte, se connecte régulièrement, copie des extraits de conversations dans un fichier partagé sur le réseau de production. En trois semaines, il a collecté des informations utiles. Il a aussi, sans le savoir, exposé l'adresse IP de son organisation sur un forum hostile, stocké des données dont la collecte n'était pas encadrée juridiquement, et créé un vecteur d'attaque potentiel entre le forum et le SI interne.
Cet exemple illustre pourquoi la collecte doit être pensée par famille de sources.
Les sources ouvertes structurées (flux RSS, bases CVE/NVD, feeds STIX/TAXII, API publiques) sont le terrain le plus simple. Collecte automatisable, données structurées, cadre juridique clair. L'enjeu n'est pas l'accès, c'est le filtrage : ces flux sont massifs, et seule une fraction concerne vos menaces prioritaires. Une plateforme comme MISP permet de mutualiser la veille entre organisations sans repartir de zéro.
Les sources sociales et semi-ouvertes (réseaux sociaux, forums publics, canaux Telegram ouverts) posent un premier palier de complexité juridique. La collecte automatisée est faisable, mais la CNIL impose le respect du RGPD, même sur des données publiquement accessibles : finalité documentée, collecte proportionnée, durée de conservation limitée. Ses recommandations sur la RIFI constituent la référence pour cadrer ces pratiques.
Les sources fermées (forums à inscription, canaux privés, serveurs restreints) combinent friction technique et juridique. Techniquement, l'automatisation requiert une infrastructure dédiée, isolée de votre SI de production (OpSec de base). Juridiquement, créer un compte sous identité dédiée pour observer un forum est possible. En revanche, accéder à un système sans autorisation ou en contournant des protections tombe sous l'article 323-1 du Code pénal. La bonne question n'est jamais « est-ce techniquement faisable ? » mais « ai-je une base légale pour y accéder ? ».
Les sources profondes (dark web, marketplaces underground) sont le terrain le plus sensible. Utiliser Tor n'est pas illégal. Ce qui l'est, c'est l'extraction et le stockage non encadrés de données, sanctionnés par l'article 323-3 du Code pénal. La frontière entre observation passive et collecte active est une ligne à ne pas franchir sans cadre juridique documenté. Ce terrain est réservé aux équipes formées, et mériterait un article dédié.
Un principe traverse toutes ces familles : votre infrastructure de collecte doit être isolée de votre SI de production. C'est parfois inconfortable, je l'entends, mais c'est une condition nécessaire pour éviter de transformer votre surveillance en vecteur d'attaque.
III. Le traitement : transformer le flux en signal contextuel
Collecter sans traiter, c'est entasser des matériaux de construction sans jamais bâtir. Vous avez du volume, mais vous n'avez pas de renseignement. Trois opérations doivent être industrialisées dans cette couche.
Le filtrage par sélecteurs
Le sélecteur, c'est le critère qui permet à votre système de distinguer, dans un flux massif, ce qui mérite d'être remonté à l'analyste. Mots-clés, expressions régulières, noms de domaines, adresses IP, pseudonymes récurrents, noms de projets internes, localisations géographiques.
Vous avez déjà fait ce travail. Vos sélecteurs découlent directement des personas construits en Épisode 1 et des sources priorisées en Épisode 2. Le nom de votre infrastructure exposée, le pseudo connu d'un acteur de menace identifié, le nom de code d'un projet sensible : ce sont vos sélecteurs naturels.
La règle d'or est ici peut-être contre-intuitive. Un signal étroit et précis vaut mieux qu'un flux large. Mieux vaut manquer une information marginale que d'en recevoir cent inutiles. L'élargissement progressif des sélecteurs, à mesure que vous maîtrisez mieux votre bruit de fond, est une pratique saine. L'inverse (partir large en espérant trier ensuite) est une promesse de noyade. L'Alert Fatigue doit être prise en compte dès la conception, et non traitée comme un problème qu'on résoudra plus tard.
L'extraction contextuelle
Imaginez qu'un de vos sélecteurs apparaisse dans une conversation sur un canal en langue étrangère que vous surveillez. Votre système détecte la mention. Mais est-ce un signal d'alerte ou du bruit ? La réponse ne dépend pas du sélecteur, elle dépend du contexte.
Ce contexte, c'est précisément ce que vous avez construit dans les deux premiers épisodes. Deux questions permettent de le mobiliser : cette mention répond-elle à une menace identifiée en Épisode 1 ? Et la source qui la produit correspond-elle à une priorité de surveillance définie en Épisode 2 ?
C'est la combinaison du sélecteur et du contexte qualifié qui justifie l'extraction d'un indicateur de compromission. Pas le sélecteur seul. Un IOC extrait sans contexte est une donnée brute. Un IOC extrait parce qu'il répond à un persona d'acteur connu, sur une source priorisée, dans un contexte aligné avec votre modèle de menaces, c'est du renseignement.
Le filtrage contextuel est votre premier rempart contre l'Alert Fatigue. On ne réduit pas le bruit en aval, on l'empêche en amont, au moment de l'extraction. Les outils de structuration d'IOC comme MISP permettent d'organiser ces extractions dans un format standardisé et de les partager entre équipes. Pour la collecte sur sources complexes (canaux fermés, flux multilingues, sources non structurées), des plateformes d'infrastructure de collecte permettent d'automatiser ce double filtre sélecteur/contexte sans exposer votre SI.
La corrélation inter-sources
Une information isolée est une anecdote. La même information croisée avec deux autres sources indépendantes devient un signal d'alerte sérieux.
Prenons un exemple concret. Une mention de votre infrastructure sur un forum underground : c'est inconfortable, mais ça peut être du bruit. Cette même mention, coïncidant avec une augmentation des tentatives de connexion sur vos systèmes exposés et une alerte CVE récente sur un de vos équipements, c'est un signal critique qui justifie une réponse immédiate.
La corrélation inter-sources permet aussi de détecter des signaux faibles qui, pris individuellement, ne déclencheraient aucune alerte. La vraie valeur d'un dispositif de surveillance mature ne réside pas dans la puissance de collecte, mais dans la capacité à relier des points que personne n'aurait reliés manuellement à temps.
IV. La livraison : le bon signal, au bon endroit, au bon moment
Une alerte critique délivrée par email à 23h, parmi quarante autres notifications de la journée, est de facto perdue. L'information juste mais délivrée trop tard ou au mauvais endroit a exactement la même valeur opérationnelle qu'une information qui n'a pas été détectée.
On pourrait penser que la livraison n'est qu'un détail technique. C'est en réalité un maillon essentiel de la chaîne de veille qui doit être clarifié avant de déployer quoi que ce soit.
Calibrer la livraison sur la criticité de la menace
La règle est simple : plus la menace est critique, plus le canal de livraison doit être direct, dédié et incontournable. On structure en trois niveaux.
- Pour une menace critique : notification immédiate sur un canal dédié (hors email), avec une astreinte humaine définie et une procédure d'escalade documentée.
- Pour une menace majeure : alerte avec seuil de déclenchement, intégration SIEM/SOAR si disponible, revue sous quatre heures.
- Pour une menace secondaire : digest quotidien ou hebdomadaire, consultation asynchrone sur un tableau de bord dédié.
On observe fréquemment une pensée organisationnelle orientée vers les astreintes pour répondre aux menaces critiques mais rarement une réflexion sur les niveaux de menaces intermédiaires. Or c'est justement le digest pour les menaces secondaires et les alertes à seuil pour les menaces majeures qui donnent de l'air à vos équipes. Sans cette hiérarchie dans les canaux de livraison, tout remonte au même niveau, et l'analyste se retrouve à traiter du bruit en priorité critique.
L'architecture des alertes doit libérer du temps de cerveau, pas en consommer.
L'outil doit servir l'analyste
Ce principe est fondamental. Il doit s'appliquer à l'ensemble des réflexions, et il n'a pas d'exception. Un outil ne doit être acquis ou mis en place que s'il réduit le temps de traitement de l'analyste. Si son ajout augmente la charge de travail sans réduire le temps de détection ou de réponse, c'est un outil qui n'a pas sa place dans votre stack, quelle que soit sa réputation.
Avant d'intégrer un nouvel outil, posez-vous quatre questions.
- Réduit-il le temps de collecte ou de tri manuel ?
- Sa maintenance est-elle automatisée ou accessible, ou requiert-elle une expertise rare ?
- Réduit-il le nombre de faux positifs par rapport à la solution actuelle ?
- L'information qu'il produit permet-elle une décision sans retraitement manuel ?
Si la réponse à l'une de ces questions est non, l'outil crée de la charge sans créer de valeur. C'est la collectionnite technique. On accumule des solutions qui demandent chacune une connexion différente, un format spécifique, une maintenance dédiée. Résultat : l'analyste passe sa journée à nourrir les outils au lieu de faire du renseignement. Notez que ces quatre critères s'appliquent aussi aux outils que vous utilisez déjà. Un outil qui avait du sens il y a deux ans peut très bien ne plus en avoir aujourd'hui si vos priorités ont changé.
V. L'arbre de décision : choisir son architecture source par source
Vous avez maintenant les briques. Il reste à les assembler. Regardez votre liste de sources priorisées issue de l'Épisode 2, et pour chacune, vous devez décider :
- quel niveau d'automatisation doit être déployé ?
- quel type de système est pertinent sur cette source ?
- quel effort de maintenance acceptable pour mon système ?
Plutôt qu'une matrice figée, je vous propose un arbre de décision en trois questions successives. Prenez chaque source de votre liste et passez-la dans cet arbre.
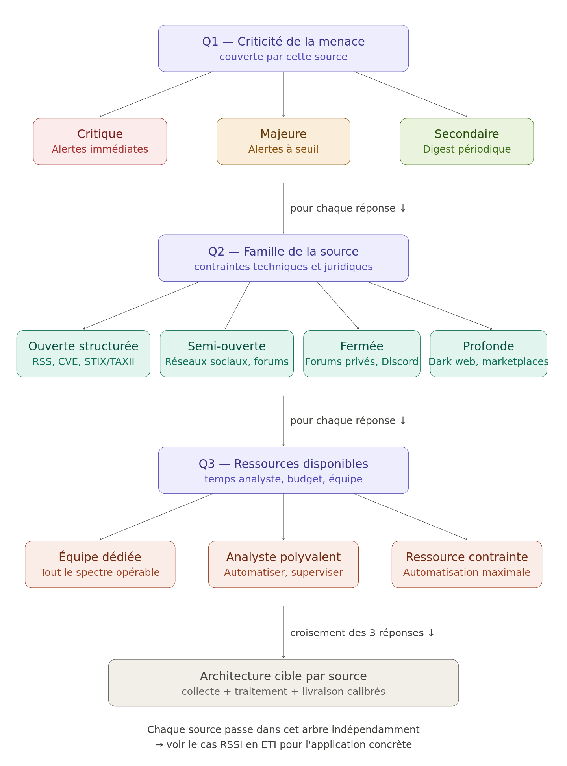
L'interopérabilité : faire communiquer les couches
Un dernier point que j'ai vu négligé dans de nombreux dispositifs et qui vient compléter cet arbre : vos outils doivent pouvoir se parler. Une alerte issue d'une source fermée concernant un nouveau groupe d'attaquants n'a pas de valeur si elle reste isolée dans son outil de collecte. Sa valeur réelle apparaît quand elle peut alimenter automatiquement votre base d'IOC pour vérifier si des indicateurs techniques sont déjà connus, ou si elle peut être poussée vers votre outil de gestion d'incidents.
Les formats standardisés comme STIX/TAXII, les webhooks et les API ouvertes sont les éléments de langage commun entre vos outils. Avant d'ajouter un outil à votre stack, vérifiez systématiquement sa capacité à s'intégrer avec ce que vous avez déjà. Un outil en silo, aussi puissant soit-il, travaille contre votre architecture.
Application concrète : le cas du RSSI seul en ETI
Appliquons ceci au cas d'un RSSI seul dans une ETI industrielle aux moyens contraints. Il a suivi les Épisodes 1 et 2. Il dispose de trois sources priorisées.
Première source : un flux CVE filtré sur ses équipements exposés. C'est une source ouverte structurée, couvrant une menace critique (exploitation de vulnérabilités sur son périmètre). On passe l'arbre.
- Criticité critique, donc automatisation et alertes immédiates.
- Source ouverte structurée, donc un agrégateur de flux CVE avec filtrage par CPE (les identifiants normalisés de vos produits et versions en production, Common Platform Enumeration) suffit.
- Ressource contrainte, donc pas de supervision continue mais des alertes par seuil envoyées sur un canal dédié (messagerie instantanée, SMS).
Concrètement : il configure un flux NVD/CVE filtré sur les CPE de ses équipements exposés, relié à un webhook qui pousse une notification sur son téléphone dès qu'une CVE critique ou exploitée (CISA KEV) le concerne. Le webhook alimente aussi un canal de notification centralisé (Slack, Mattermost, ou un simple outil de ticketing) où convergeront les alertes des autres sources. Temps de mise en place : une demi-journée. Maintenance : quasi nulle, mise à jour de la liste CPE une fois par trimestre.
Deuxième source : un forum underground où son secteur industriel est régulièrement mentionné. C'est une source fermée, couvrant une menace critique (revente d'accès, discussions de ciblage sectoriel). On passe l'arbre.
- Criticité critique, donc il ne peut pas ignorer cette source.
- Source fermée, donc infrastructure dédiée et cloisonnée obligatoire.
- Ressource contrainte, donc la collecte manuelle quotidienne est inenvisageable.
La réponse : s'appuyer sur une plateforme de collecte automatisée sur sources fermées (type HubFeed) qui déploie des agents dédiés, filtre sur ses sélecteurs (nom de l'entreprise, secteur, noms de domaine), et remonte les mentions qualifiées sous forme d'alertes. Il ne va jamais sur le forum lui-même. Il reçoit un signal pré-filtré, poussé via webhook vers le même canal centralisé que ses alertes CVE. Temps de mise en place : configuration des sélecteurs en une journée. Maintenance : revue des sélecteurs une fois par mois.
Troisième source : une veille presse spécialisée sur son secteur. C'est une source ouverte, couvrant une menace secondaire (évolutions réglementaires, tendances sectorielles). On passe l'arbre.
- Criticité secondaire, donc un digest suffit.
- Source ouverte, donc un simple agrégateur RSS ou une alerte Google configurée sur les bons mots-clés fait le travail.
- Ressource contrainte, donc consultation hebdomadaire, pas plus.
Concrètement : il agrège quelques flux RSS sectoriels dans un lecteur, qu'il consulte le lundi matin en 15 minutes. Ni alerte, ni notification, ni infrastructure derrière. Pas besoin d'interopérabilité ici : une menace secondaire ne justifie pas de nourrir le canal centralisé.
Résultat pour la semaine suivante : son flux CVE tourne en continu et le notifie uniquement quand un équipement exposé est concerné par une vulnérabilité exploitée. Sa surveillance du forum underground lui remonte les mentions qualifiées sans qu'il ait à s'y connecter. Sa veille presse l'attend dans un agrégateur qu'il consulte à son rythme. Les deux sources critiques convergent vers un canal unique où les signaux peuvent être lus ensemble : une mention de son secteur sur le forum, le même jour qu'une CVE exploitée sur un de ses équipements, ce n'est plus deux alertes séparées, c'est un signal corrélé qui justifie une action immédiate. Trois sources, trois niveaux de traitement, un point de convergence pour ce qui compte. Plus besoin d'aller scroller un forum à 7h du matin pour savoir si quelque chose a bougé. Le système tient même quand notre RSSI est en déplacement ou en congé.
Conclusion
Un système de surveillance se conçoit dans l'ordre : collecter, traiter, livrer, décider. Inverser cet ordre (acheter l'outil avant de définir l'architecture) est l'erreur qui explique pourquoi tant de dispositifs de veille finissent par générer plus de bruit que de signal. En suivant la logique de cette série, vous avez maintenant les quatre piliers d'un plan de veille opérationnel :
- une cartographie des menaces (Épisode 1) ;
- une qualification de vos sources (Épisode 2) ;
- une priorisation des sources (Épisode 2) ;
- une architecture technique alignée sur vos priorités, vos ressources et votre cadre juridique.
La force de votre dispositif ne réside plus dans la puissance d'outils pris isolément mais dans leur capacité à fonctionner ensemble, de manière autonome et pérenne. Cette architecture ne dépend plus d'un seul homme. On supprime enfin le risque de voir votre veille s'effondrer le jour où votre meilleur analyste prend ses congés.
Concevoir le système est une chose. L'opérer au quotidien en est une autre. Comment lancer les premières collectes sans tout casser ? Comment organiser la journée de l'analyste pour qu'il fasse du renseignement et pas de l'administration d'outils ? Comment détecter qu'une source s'est tarie ou qu'une nouvelle menace justifie de reconfigurer le dispositif ? Ce sont les questions auxquelles nous nous attaquerons dans le prochain épisode.