Série : Construire son plan de veille ← Précédent : Ep. 3 — Concevoir son système de veille
Si vous avez bien suivi les précédents articles vous devriez maintenant avoir une bonne sélection de sources, une architecture de collecte et de traitement adaptée et un go live prêt à être lancé. Sur le papier, votre dispositif de surveillance est prêt. Il ne reste plus qu'à appuyer sur le bouton.
Sauf que votre dispositif peut mourir de deux façons.
La première est spectaculaire. Vous branchez tout un lundi matin. Mardi soir, le canal centralisé affiche plusieurs centaines de notifications. Mercredi, les analystes commencent à les ignorer. Vendredi, le système est officieusement abandonné. On avait tout fait pour éviter l'Alert Fatigue et le système est tout de même mort par saturation. C'est le scénario que tout le monde redoute, et celui contre lequel on tente de se prémunir le plus instinctivement.
La seconde est silencieuse. Votre dispositif tourne, les alertes arrivent, personne ne se plaint. Mais en coulisses, deux sources se sont taries sans que personne ne le remarque. Cinq sélecteurs ne matchent plus rien depuis des semaines. Trois autres ramènent du bruit sur des menaces reclassées il y a quatre mois. L'analyste trie consciencieusement un flux dont un tiers est devenu inutile. Et le jour où le signal critique arrive, il est noyé dans ce bruit de fond que tout le monde avait cessé de questionner. C'est ce que j'appelle la dette de veille. Et c'est le scénario qui fait le plus de dégâts, précisément parce que personne ne le voit venir.
Cet épisode traite de ces deux risques. Plus orienté sur la méthode, il traite du déploiement de votre système de veille et de la discipline nécessaire pour le faire vivre. C'est armé de cette méthode qu'on va s'assurer de déployer un dispositif produisant du renseignement plutôt que du bruit.
C'est l'épisode final de cette série. Nous allons boucler les deux étapes restantes du plan :
- Cartographie et qualification des menaces (Ep. 1)
- Évaluation et priorisation de la veille (Ep. 2)
- Cartographie et qualification des sources d'informations (Ep. 2)
- Identification des systèmes de veille sur les sources d'informations (Ep. 3)
- Mise en place du dispositif de surveillance (Cœur de cet article)
- Maintenir et faire évoluer la veille dans le temps (Cœur de cet article)
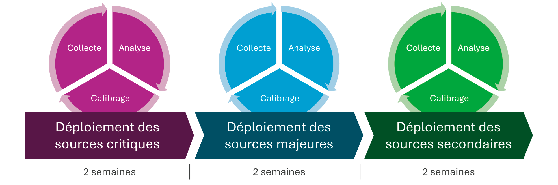
I. Déployer et calibrer par vagues
Le réflexe naturel, une fois l'architecture définie, serait de brancher le système et d'en apprécier les résultats. On a fait le travail préparatoire, on a les outils, on veut voir le système tourner. C'est compréhensible. C'est aussi un des meilleurs moyens de le tuer dans l'œuf.
Chaque source, même bien qualifiée, génère du bruit à l'allumage. Les sélecteurs ne sont pas encore calibrés sur le flux réel. Les faux positifs n'ont pas encore été identifiés. Multiplier les sources actives dans ces conditions, c'est multiplier le bruit à un moment où vous n'avez pas encore les repères pour l'identifier et le trier rapidement.
La logique qui fonctionne est celle du déploiement par vagues, aligné sur vos priorités. Vous commencez par vos sources critiques (P0), vous observez le bruit, vous calibrez les sélecteurs. Si vos P0 génèrent un bruit ingérable, inutile d'ajouter le reste. On règle d'abord le problème de bruit P0 et on stabilise le signal. Une fois la première vague stabilisée, vous branchez vos sources majeures (P1). On répète alors le processus et on s'assure du bon fonctionnement des croisements d'informations entre sources. Les sources secondaires arrivent en dernier, le coût d'un retard étant faible et les risques associés limités.
Une temporalité de deux semaines de travail par typologie de source (critique / majeure / secondaire) est une bonne métrique. Cela donne le temps d'observer la production de données et de l'ajuster. Un déploiement total en un jour peut être satisfaisant, mais il y a peu de chance qu'il survive au bruit qui frappera en lame de fond votre dispositif.
Il est essentiel dans cette phase d'ajustement de documenter les calibrages effectués sur les sélecteurs. Qu'il s'agisse d'élargissement, de restrictions de sélecteurs, ou de requalification de sources, vous vous remercierez vous-même d'avoir documenté ces changements lorsque vous remettrez le nez dedans six mois plus tard.
Notons aussi que durant cette phase de rodage, les alertes ne sont pas opérationnelles. Votre dispositif n'est pas encore pleinement déployé. Vous pouvez en exploiter les données, mais les alertes ne doivent pas mener à des prises d'actions critiques sans analyse plus approfondie.
II. La dette de veille
En développement logiciel, la dette technique désigne l'accumulation de raccourcis, de composants non maintenus et de choix temporaires devenus permanents. Elle ne se voit pas au quotidien. Elle se paie le jour où il faut faire évoluer le système et que tout casse.
Le même phénomène existe dans un dispositif de surveillance. Je l'ai vu dans suffisamment d'organisations pour lui donner un nom : la dette de veille. Et comme la dette technique, elle a un principal, un taux d'intérêt et un point de défaut.
Le principal, c'est le nombre de composants non revus dans votre dispositif. Des sélecteurs qui n'ont pas bougé depuis six mois. Une source éteinte (un forum qui a fermé, un canal Telegram qui a changé de sujet, une API qui a changé) que personne n'a remarquée parce qu'elle ne produisait déjà plus grand-chose depuis des semaines. Des priorités de menaces qui ont évolué (un nouveau produit exposé, une nouvelle géographie d'activité, l'acquisition d'une filiale) sans que le plan de veille ait suivi. Tous ces éléments s'accumulent et vont devoir être corrigés un jour. C'est le principal de votre dette.
Le taux d'intérêt, c'est le temps de triage perdu chaque jour. Chaque source obsolète, chaque sélecteur qui ne correspond plus à rien consomme du temps de traitement sans produire de valeur. L'analyste ne s'en rend pas toujours compte parce que la dégradation est progressive. C'est un faux positif de plus par-ci, un résultat vide de plus par-là. Rien de dramatique isolément. Mais avec un principal qui évolue et augmente dans le temps, vos intérêts évoluent aussi. Au fur et à mesure, le temps de l'analyste se voit consommé par les intérêts de la dette.
Le défaut, c'est l'incident. Le jour où le signal critique arrive et se noie dans le bruit de fond de cette dette accumulée. L'alerte qui comptait vraiment a été noyée parmi les notifications d'une source morte et les résidus d'un sélecteur qui ne filtre plus rien depuis des mois.
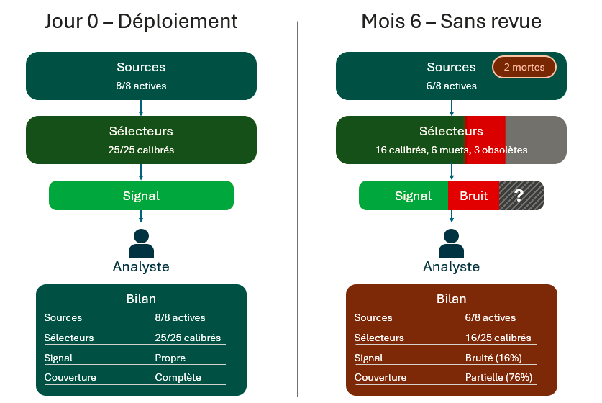
Mettons des chiffres, même schématiques. Votre dispositif démarre avec huit sources et vingt-cinq sélecteurs (trente-trois composants donc). Six mois plus tard, sans revue sérieuse, deux sources sont mortes, six sélecteurs ne matchent plus rien et trois autres ramènent du bruit sur des menaces reclassées.
Sur les trente-trois composants qui forment votre dispositif, le tiers n'est plus fonctionnel. D'une part, on est devenu, sans le savoir, aveugle sur probablement plus d'un quart des sources d'intérêt (les deux sources mortes et les sélecteurs incohérents). D'autre part, le bruit qui s'est lentement ajouté au dispositif génère un travail supplémentaire de tri à notre analyste. Le système entier est en train de s'effondrer mais puisqu'on reçoit de la donnée, tout va bien non ?
J'ai vu des organisations préférer se noyer dans la donnée plutôt que de couper une seule source qui ne leur apportait que des informations secondaires. La raison invoquée est toujours la même : « au cas où ». Cette prudence est compréhensible. Mais elle a un coût réel. Chaque source conservée « au cas où » consomme du temps de triage, génère du bruit, et contribue à masquer les signaux qui comptent. Le « au cas où » est l'ennemi silencieux de la performance de votre dispositif. Le ratio Signal / Bruit doit être une véritable boussole.
III. Le cadre de revue : prévenir la mort lente
La dette de veille ne se règle pas en une fois. C'est un problème chronique qui reviendra autant de fois que vous l'ignorerez. Le seul système de prévention adéquat est un cadre de revue régulier, appliqué avec discipline. Ce cadre se structure en quatre niveaux de maintenance. Si vous n'avez pas les moyens de déployer le cadre dans son intégralité, focalisez-vous sur les deux premiers niveaux et intégrez les deux suivants dans des systèmes organisationnels déjà existants. Soyez toutefois conscients que faire ce dernier choix revient à s'orienter sciemment vers un mode dégradé.
Premier niveau : le réflexe quasi-quotidien
C'est le regard critique de l'analyste sur ce que le système produit. Pas une revue formelle mais un réflexe d'hygiène de veille.
- Est-ce que je suis satisfait de ce que je reçois ?
- Y a-t-il eu un loupé, une information que j'aurais dû voir et qui m'est parvenue par un autre canal ?
- Quel est mon délai entre la détection par le système et l'origine réelle du problème ?
L'analyste qui ne se pose plus ces questions est un analyste qui va rapidement commencer à subir son système. C'est le premier symptôme de la dette.
Deuxième niveau : le contrôle hebdomadaire
C'est le minimum vital de maintenance.
- Mes sélecteurs produisent-ils encore ?
- Mes sources sont-elles toujours actives ?
- Mes sources produisent-elles toujours des données d'intérêt (ex. : chaîne Telegram qui change de sujet) ?
Un sélecteur muet depuis une semaine sur une source critique, c'est un signal à investiguer immédiatement. Une source qui a changé de format ou de fréquence de publication mérite une vérification. Sans cette revue, vous ne saurez jamais si votre système se dégrade. Avec, vous maîtrisez son état à tout moment, et surtout, vous en préviendrez les dérives avant qu'elles ne produisent un bruit incontrôlable.
Troisième niveau : la revue mensuelle
On prend de la hauteur. On regarde le dispositif dans son ensemble :
- Comment évolue le rapport signal / bruit ?
- Les alertes traitées ce mois-ci ont-elles produit des décisions, ou tourne-t-on à vide ?
- Le croisement des sources fait-il toujours sens au regard de leurs thématiques, fréquence et fiabilité de production ?
C'est à ce niveau qu'on identifie qu'une source consomme du temps sans produire de valeur décisionnelle, et qu'on pose la question de la couper. C'est aussi le moment de vérifier que les outils en place répondent toujours aux quatre critères de l'Épisode 3.
Quatrième niveau : la revue trimestrielle
Là, on revient aux fondamentaux. On reprend les Épisodes 1 et 2, même succinctement.
- La cartographie des menaces est-elle toujours alignée avec la réalité de l'organisation ?
- Votre surface de vulnérabilité a-t-elle changé ?
- Un changement a-t-il modifié le profil de vos acteurs de menace ?
C'est ici qu'on prend les décisions structurantes : reclasser une menace, réorienter le dispositif, se séparer de clusters complets… C'est le moment où vous devez vous demander si le plan de surveillance tel qu'il est défini fait toujours sens au regard des objectifs, moyens et risques de votre organisation.
Si votre organisation n'a pas les moyens de tenir les quatre niveaux, voici mon conseil : tenez les deux premiers avec rigueur, et bloquez un créneau mensuel même court ou informel. La revue trimestrielle peut s'intercaler dans un comité existant. Ce qui tue un dispositif, ce n'est pas l'absence de revue stratégique annuelle. C'est l'absence de contrôle technique hebdomadaire pendant que les sources se dégradent en silence. La priorité doit être donnée au contrôle opérationnel.
Implications managériales
La présentation de ces quatre niveaux de contrôle peut sembler très bureaucratique. On voit d'ici les montagnes de papiers et de notes s'accumuler pour justifier de la décision de supprimer une source, de la mise à jour d'une API… Ce ne doit pas être le cas.
L'aspect bureaucratique de cette méthode ne dépend que du système managérial que vous appliquez à votre plan de surveillance. Un canevas simple et court peut permettre de documenter aisément et rapidement tout changement appliqué au niveau opérationnel. La revue de quelques morceaux du plan de veille ne nécessite pas une réunion de quatre heures avec tous les membres du CODIR et leurs adjoints.
Dans le même ordre d'idées il est important de noter la priorité donnée au volet opérationnel dans ce cadre. Un analyste qui ne dispose d'aucune latitude dans l'évolution et l'affinement des modules de surveillance dont il a la charge ne pourra jamais prévenir efficacement la dette de veille. Celle-ci semblera provenir de problèmes techniques, alors que son origine réelle sera organisationnelle. Il est donc essentiel dans la mise en place de votre plan de surveillance de penser le système humain que vous allez adosser à la technique.
- Quelle marge de manœuvre chaque personne de l'équipe peut-elle avoir sur ses modules ?
- Quel devoir de reporting montant et descendant impose-t-on à chaque échelon du dispositif ?
- Quels systèmes de suivi et de communication utilise-t-on pour fluidifier le système managérial en place ?
Aussi fin que soit votre dispositif de surveillance sur le papier, il se heurtera toujours au management mis en place autour de lui. In fine ce seront des humains qui exploiteront le renseignement. Votre système managérial, votre culture d'entreprise impacteront et modifieront invariablement votre surveillance et la qualité du renseignement qui en émergera. C'est peut-être là une des variables d'ajustement les plus complexes à appréhender dans la mise en place d'un bon dispositif de veille.
IV. Traiter l'alerte comme outil d'amélioration
Reprenons notre RSSI seul en ETI du dernier épisode. Sa première source branchée est le flux CVE filtré par CPE. Il s'attèle d'abord à bien cadrer sa liste CPE. Elle est peut-être incomplète (il a oublié un équipement réseau ajouté récemment) ou trop large (elle inclut des versions de logiciels qu'il n'utilise plus). Il ajuste ses sélecteurs puis se focalise sur sa deuxième source (le forum underground via sa plateforme de collecte) et recommence le calibrage. Après quelques temps, son dispositif est calibré et le rythme est en place.
Un matin, notre RSSI ouvre son canal centralisé et trouve deux signaux qui n'ont en apparence rien à voir entre eux. Sa plateforme de collecte sur le forum underground a remonté une mention pendant la nuit : un acteur propose des accès VPN dans son secteur industriel. Le matin, son flux CVE l'a notifié d'une vulnérabilité activement exploitée sur un de ses équipements réseau exposés.
Le premier réflexe, c'est la qualification. La mention sur le forum d'abord. Est-ce du bruit sectoriel générique ou quelque chose de plus ciblé ? L'acteur correspond-il à un profil identifié dans sa cartographie de l'Épisode 1 ? Quelle est la fiabilité de cette source (cf. le Code d'Amirauté de l'Épisode 2). Côté CVE, la question est plus directe. L'équipement concerné est-il encore en production, ou est-ce un résidu de sa liste CPE pas encore nettoyé ?
S'il s'avère que la mention est générique et la CVE concerne une version qu'il n'utilise pas, il documente le faux positif et ajuste éventuellement un sélecteur si ce cas se répète. Affaire classée.
Mais supposons que la mention soit spécifique. Il passe alors à l'enrichissement. Que disent les autres sources ? Y a-t-il des indicateurs techniques associés qu'il peut croiser avec ses journaux de connexion ? Notre RSSI n'a peut-être pas de SIEM, mais il a accès aux logs de son firewall et de ses équipements exposés. Dans un CERT équipé, cette étape passerait par un croisement automatisé avec la base MISP. Ici, c'est plus artisanal, mais la logique est la même, on cherche la corrélation.
Et si la corrélation est là, une mention spécifique de son secteur, une CVE exploitée sur un équipement exposé, peut-être des connexions inhabituelles dans les logs, alors le signal est sérieux. Notre RSSI n'hésite pas : patch d'urgence, isolation de l'équipement et notification à sa direction.
Ce qui compte dans ce scénario, ce n'est pas seulement la décision finale. C'est la boucle de retour. Un faux positif récurrent entraîne un ajustement de sélecteur. Un vrai signal enrichit la base d'IOC et peut justifier l'ajout d'une nouvelle source. Si l'incident révèle un angle mort, une menace qui s'est concrétisée sans signal préalable, c'est le signe qu'il manque une source ou un sélecteur dans le dispositif. Chaque alerte traitée affine le système. C'est un cycle d'amélioration continue qui gagne en précision à chaque itération.
Conclusion
En quatre épisodes, nous sommes passés d'une feuille blanche à un dispositif de surveillance opérationnel. Cartographier les menaces. Qualifier et prioriser les sources. Concevoir l'architecture technique. Déployer, calibrer, et maintenir le système dans le temps.
Le fil rouge de cette série a toujours été le même : voir ce qui compte, au bon moment, et pouvoir agir dessus. Un dispositif de surveillance n'est pas une collection d'outils et de sources destinée à vous rendre omniscient. C'est un système conçu pour vous aider à prendre des décisions complexes sur des sujets d'incertitude.
Si ce système est bien conçu et bien maintenu, il ne dépend plus d'un seul homme. Le « Script Hero » de l'article fondateur de cette série, cet analyste solitaire qui porte à bout de bras les scripts de collecte et sans qui tout s'effondre, peut enfin partir en congé. Le dispositif tourne. Les alertes arrivent. Les revues sont en place. On a transféré la résilience d'un individu vers un système.
Mais ce système ne peut être pérenne qu'à la condition de prévenir la dette de veille. Elle ne fera jamais de bruit. Elle ne déclenchera aucune alerte. Elle ne génèrera aucun ticket. Elle s'installera progressivement dans les interstices du dispositif, entre une source morte et un sélecteur oublié, et elle attendra patiemment le jour où elle vous coûtera un incident que vous auriez dû voir venir.
Construire un plan de veille, c'est le travail d'un mois. L'empêcher de se dégrader, c'est le travail de tous les jours. Et c'est probablement la partie la plus difficile, parce que personne ne vous félicitera pour un incident qui ne s'est pas produit. Mais entre nous, le jour où tout le monde connaît votre nom dans l'entreprise, c'est rarement pour une bonne nouvelle.